About me
I am Ziyuan Huang, a research scientist at Ant Group, advancing omni-modal intelligence - next frontier of artificial general intelligence. My work focuses on a foundational breakthrough: a unified model grounded in unified representations that unlocks deep cross-modal and cross-task synergy, moving beyond isolated perception or generation pipelines. This enables AI systems that can truly assist, create and collaborate with people in complex, real-world contexts, intuitively, coherently, and across any modality.
I earned my Ph.D. degree from National University of Singapore in 2023 under the supervision of Prof. Marcelo Ang. Prior to Ant, I have spent wonderful times conducting research in the MARS Lab under Professor Zhao Hang, TONGYI under Dr. Zhang Shiwei, and Vision4Robotics Group at Tongji University under Professor Fu Changhong. I am also fortunate to have worked closely with Dr. Pan Liang and Professor Liu Ziwei in S-Lab@NTU.
We are actively hiring self-motivated full-time research scientists and interns to work on cutting-edge research projects on unified omni-modal models. Feel free to drop me an email if you are interested!
Selected technical reports
For a full publication list, please refer to my Google Scholar.
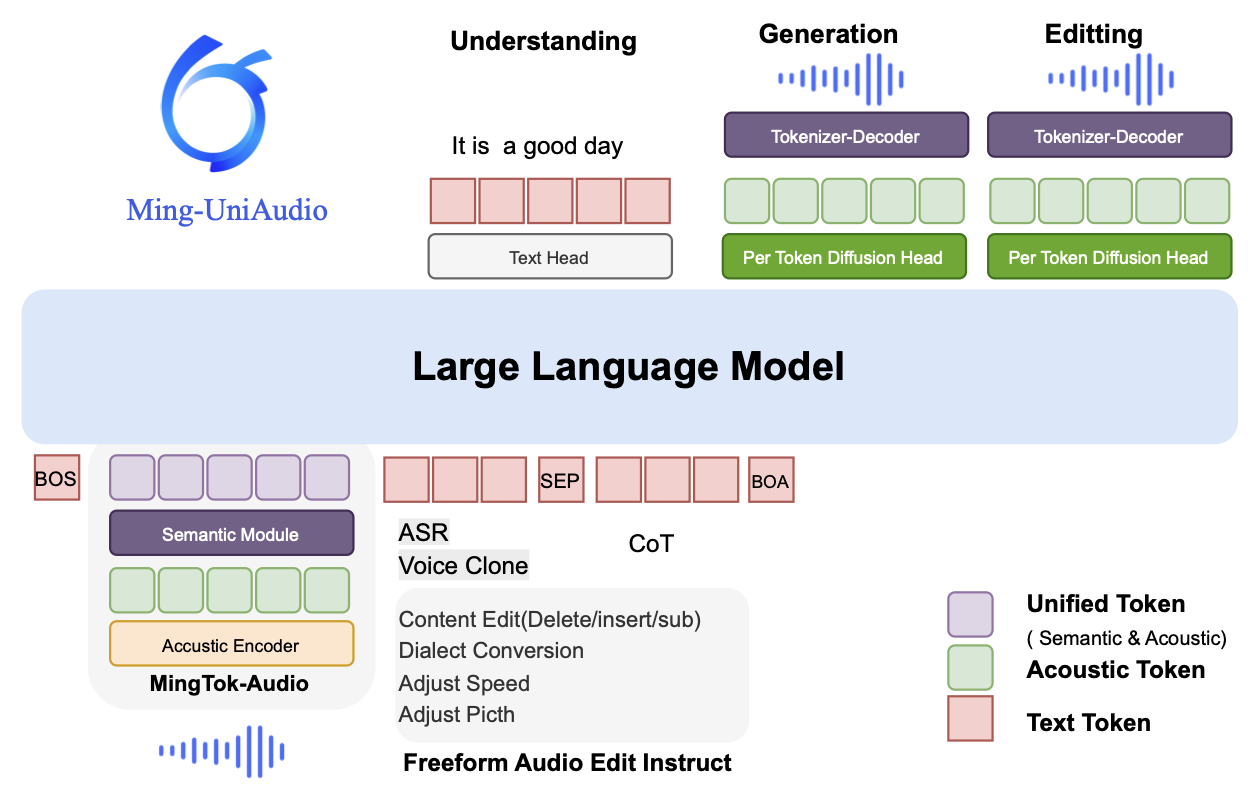
Ming-UniAudio: Speech LLM for Joint Understanding, Generation and Editing with Unified Representation
Canxiang Yan, Chunxiang Jin, Dawei Huang, Haibing Yu, Han Peng, Hui Zhan, Jie Gao, Jing Peng, Jingdong Chen, Jun Zhou, Kaimeng Ren, Ming Yang, Mingxue Yang, Qiang Xu, Qin Zhao, Ruijie Xiong, Shaoxiong Lin, Xuezhi Wang, Yi Yuan, Yifei Wu, Yongjie Lyu, Zhengyu He, Zhihao Qiu, Zhiqiang Fang, Ziyuan Huang
A unified audio model for understanding, generating, and editing audio contents, based on unified representations.
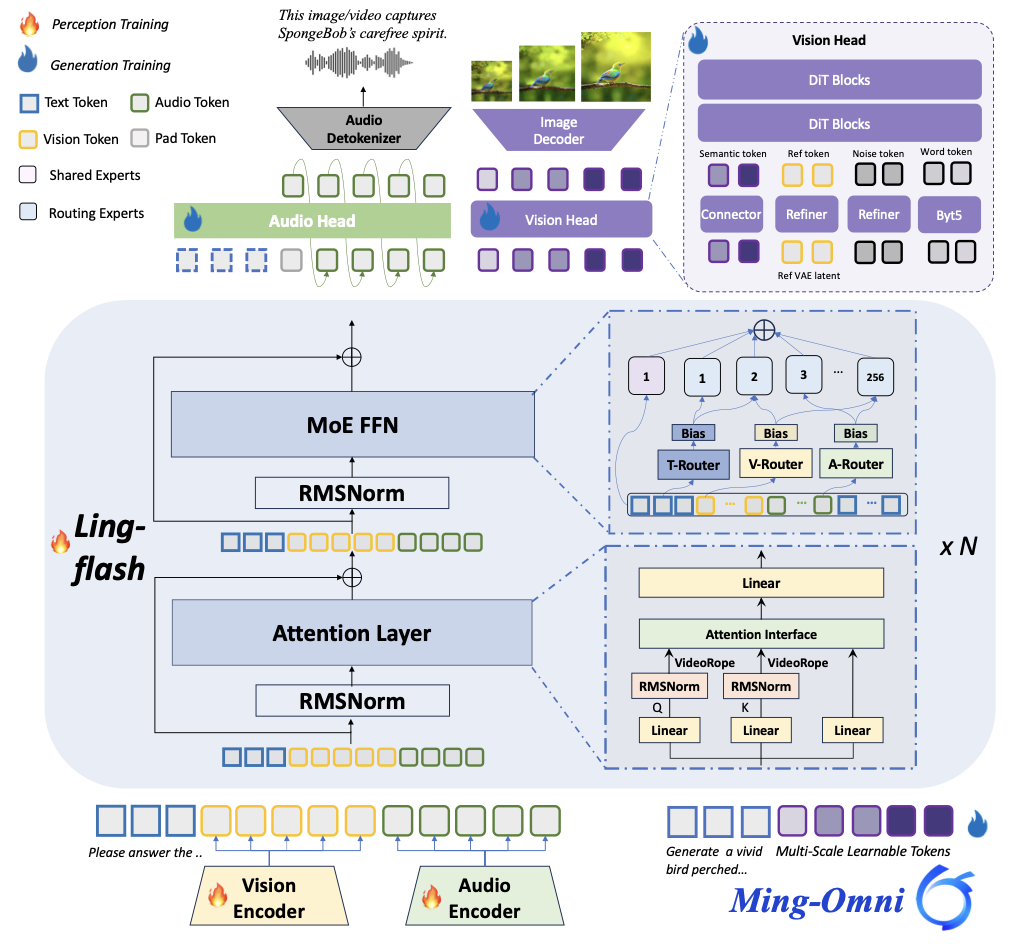
Ming-UniVision: Joint Image Understanding and Generation with a Unified Continuous Tokenizer
Ziyuan Huang, DanDan Zheng, Cheng Zou, Rui Liu, Xiaolong Wang, Kaixiang Ji, Weilong Chai, Jianxin Sun, Libin Wang, Yongjie Lyv, Taoye Huang, Jiajia Liu, Qingpei Guo, Ming Yang, Jingdong Chen, Jun Zhou
A unified MLLM for understanding, generating and editing visual contents that seamlessly supports multi-round interactions, all powered by the first-ever continuous unified visual representations.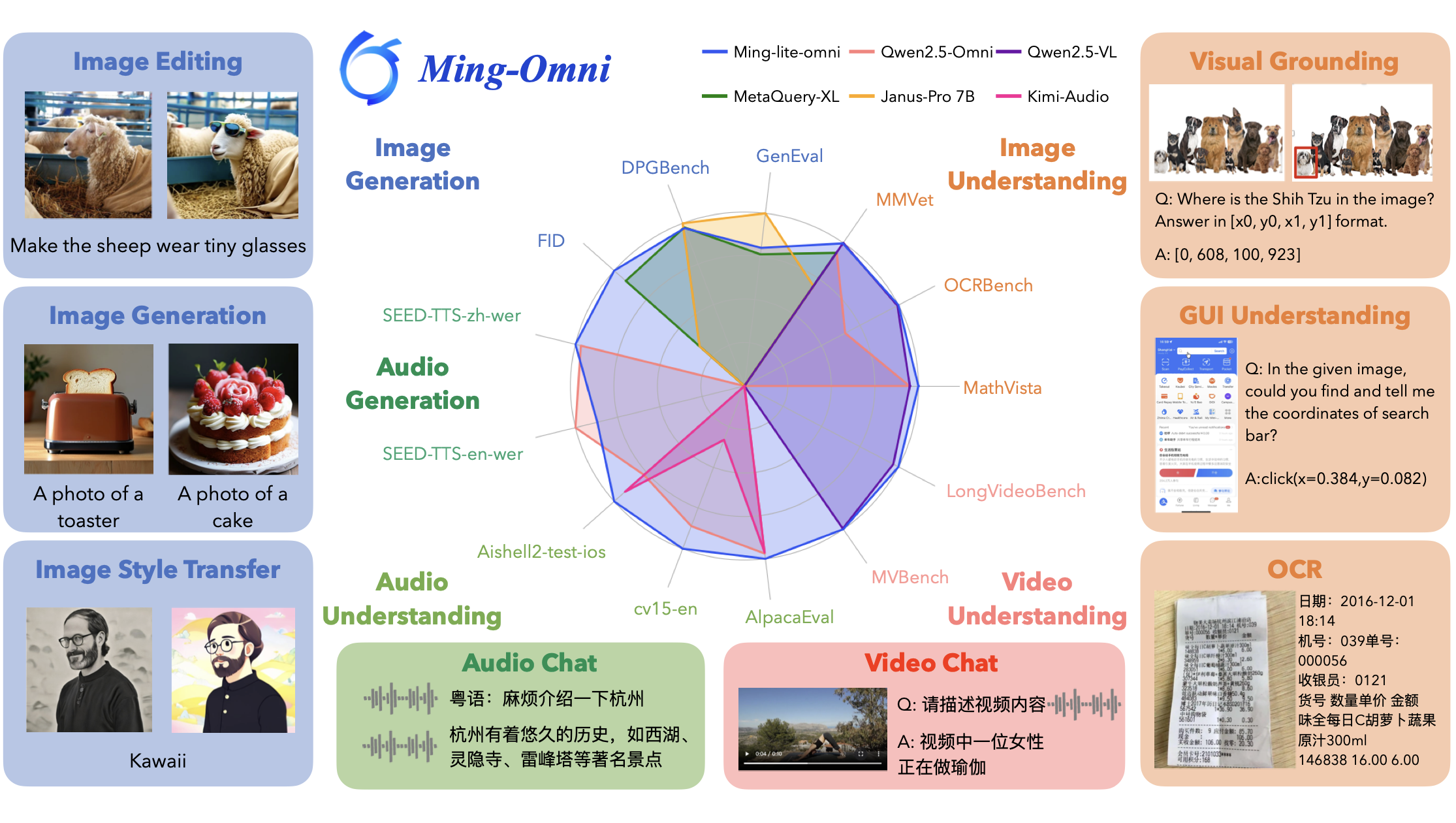
Selected publications

ARGenSeg: Image Segmentation with Autoregressive Image Generation Model
Xiaolong Wang, Lixiang Ru, Ziyuan Huang, Kaixiang Ji, Dandan Zheng, Jingdong Chen, Jun Zhou
NeurIPS 2025.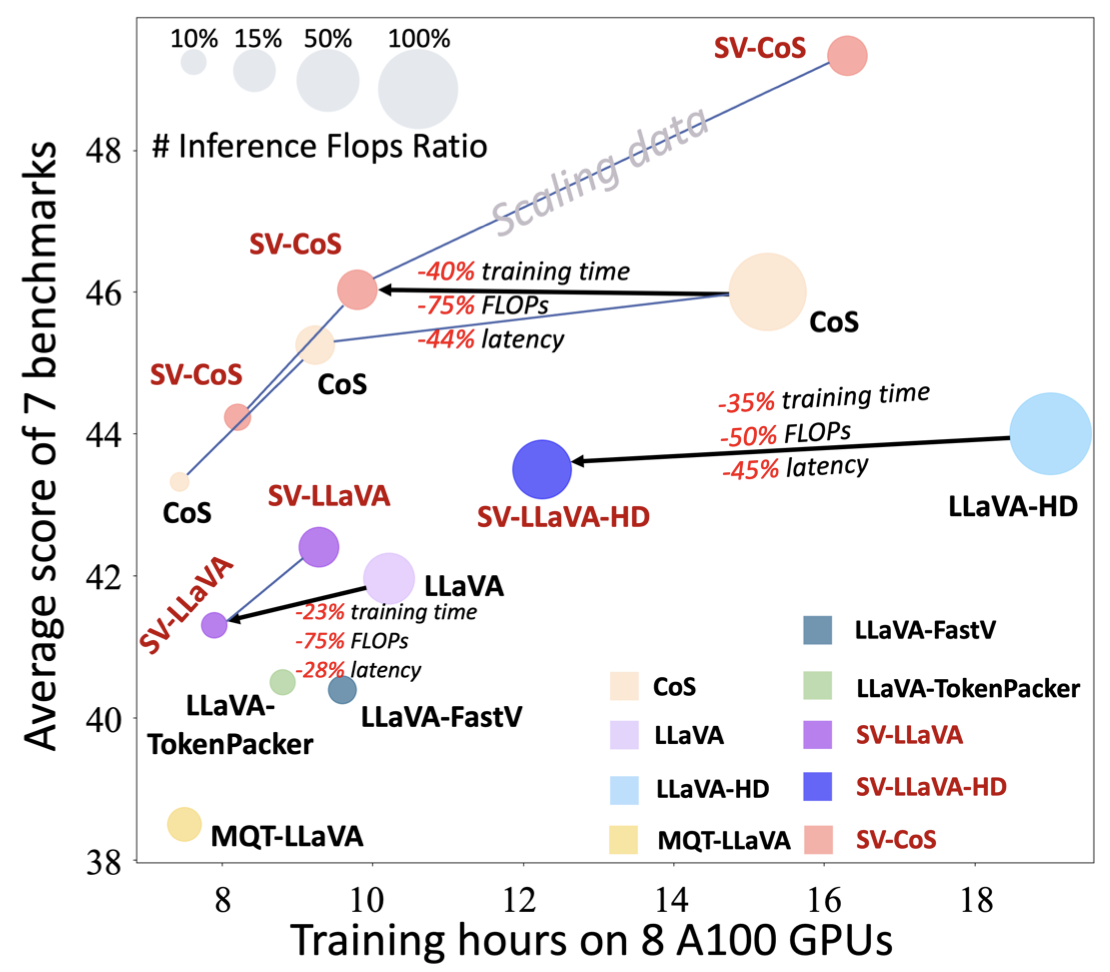
Skip-Vision: Efficient and Scalable Acceleration of Vision-Language Models via Adaptive Token Skipping
Weili Zeng, Ziyuan Huang, Kaixiang Ji, Yichao Yan
ICCV 2025.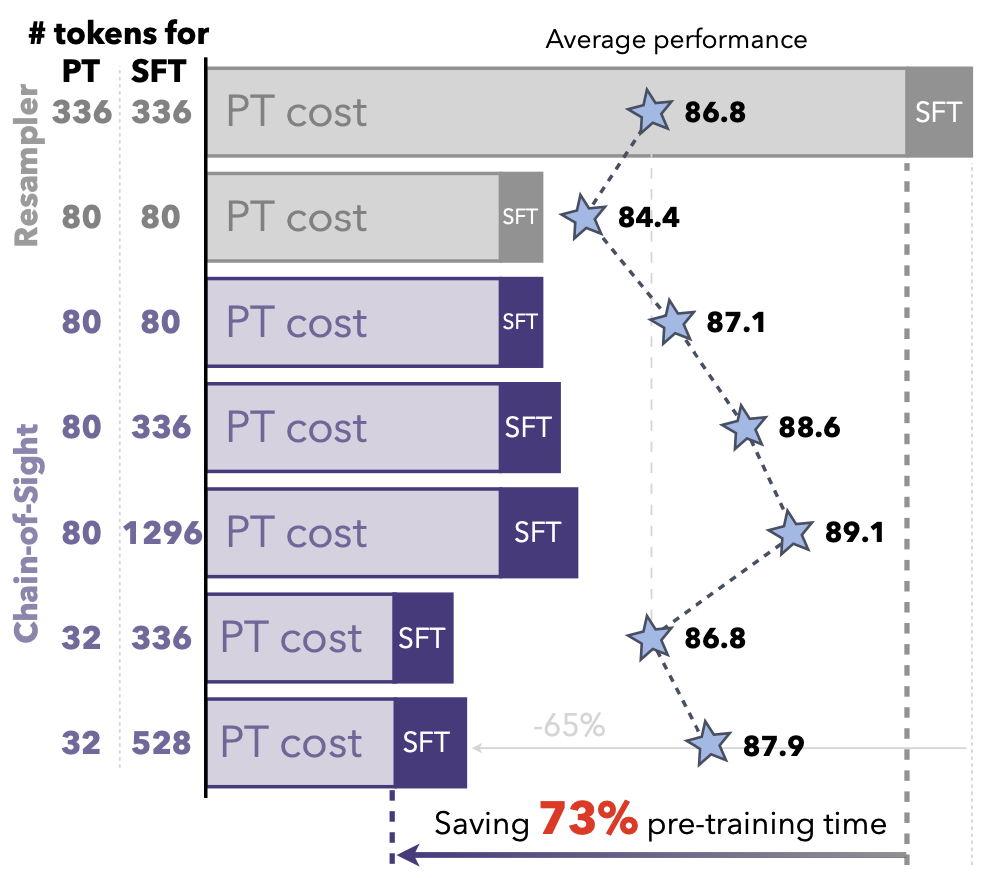
Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight
Ziyuan Huang, Kaixiang Ji, Biao Gong, Zhiwu Qing, Qinglong Zhang, Kecheng Zheng, Jian Wang, Jingdong Chen, Ming Yang
NeurIPS 2024.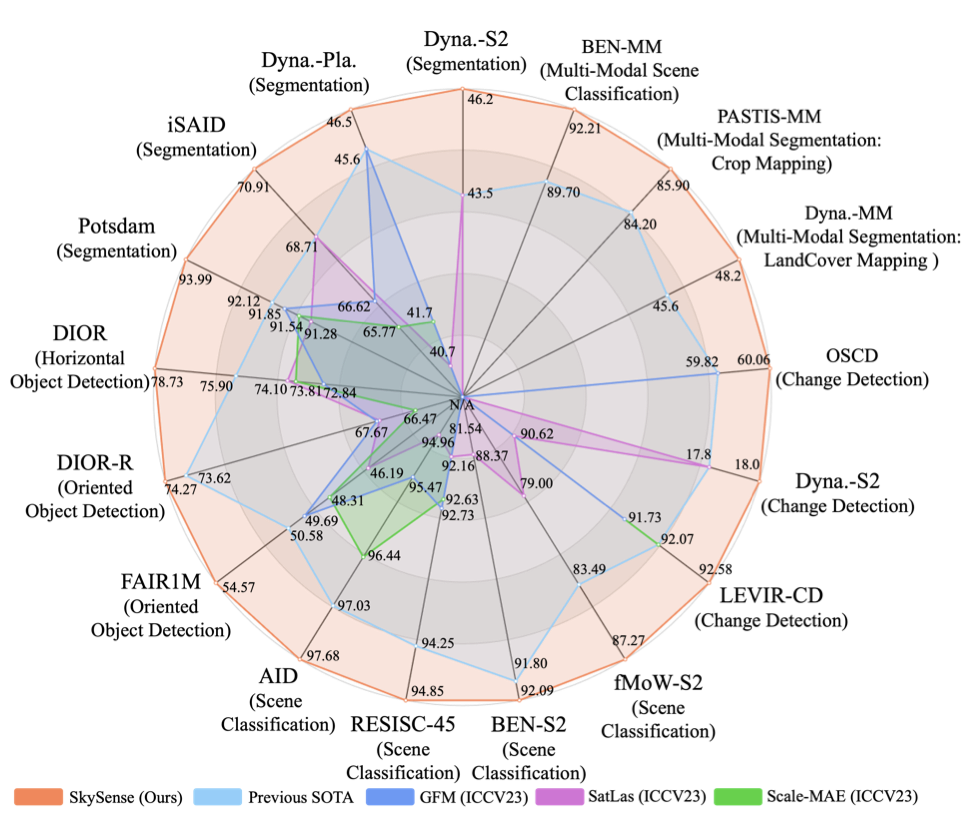
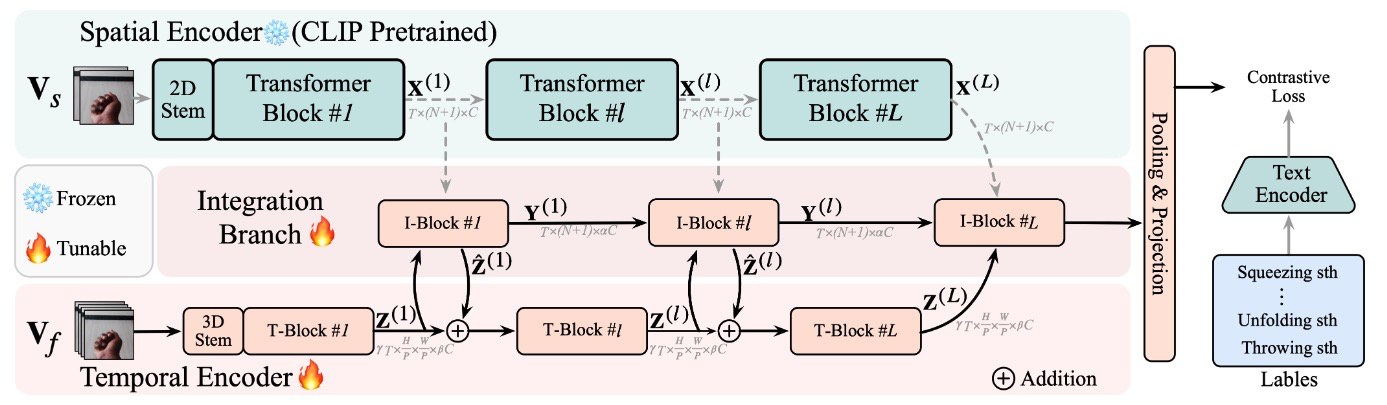
Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery
Xin Guo, Jiangwei Lao, Bo Dang, Yingying Zhang, Lei Yu, Lixiang Ru, Liheng Zhong, Ziyuan Huang, Kang Wu, Dingxiang Hu, Huimei He, Jian Wang, Jingdong Chen, Ming Yang, Yongjun Zhang, Yansheng Li
CVPR 2024.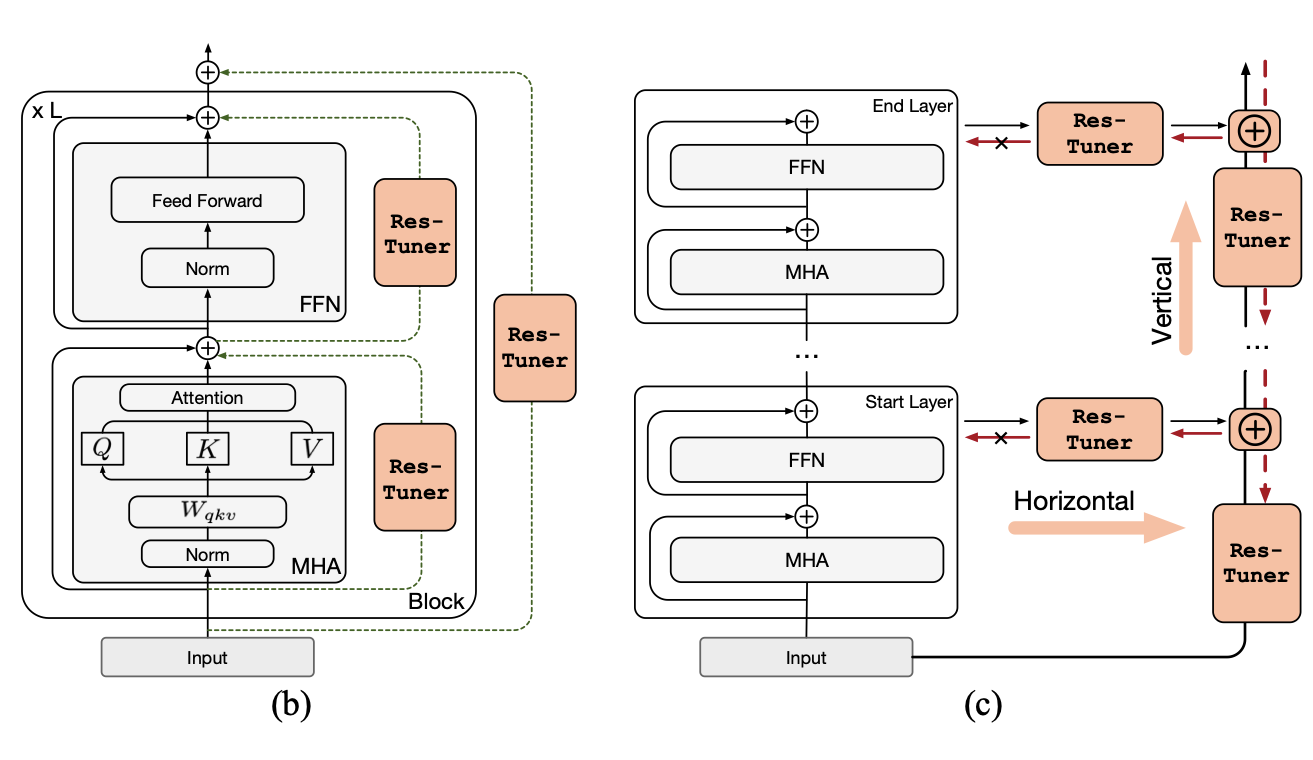
Res-tuning: A flexible and efficient tuning paradigm via unbinding tuner from backbone
Zeyinzi Jiang, Chaojie Mao, Ziyuan Huang, Ao Ma, Yiliang Lv, Yujun Shen, Deli Zhao, Jingren Zhou
NeurIPS 2024.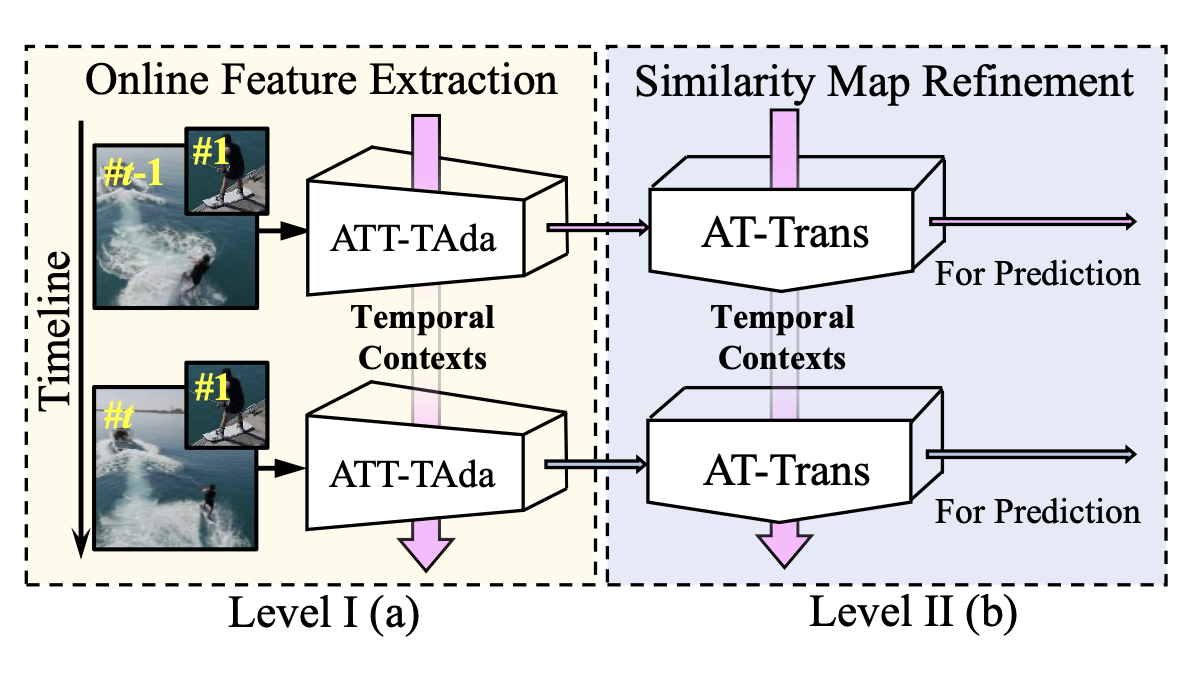
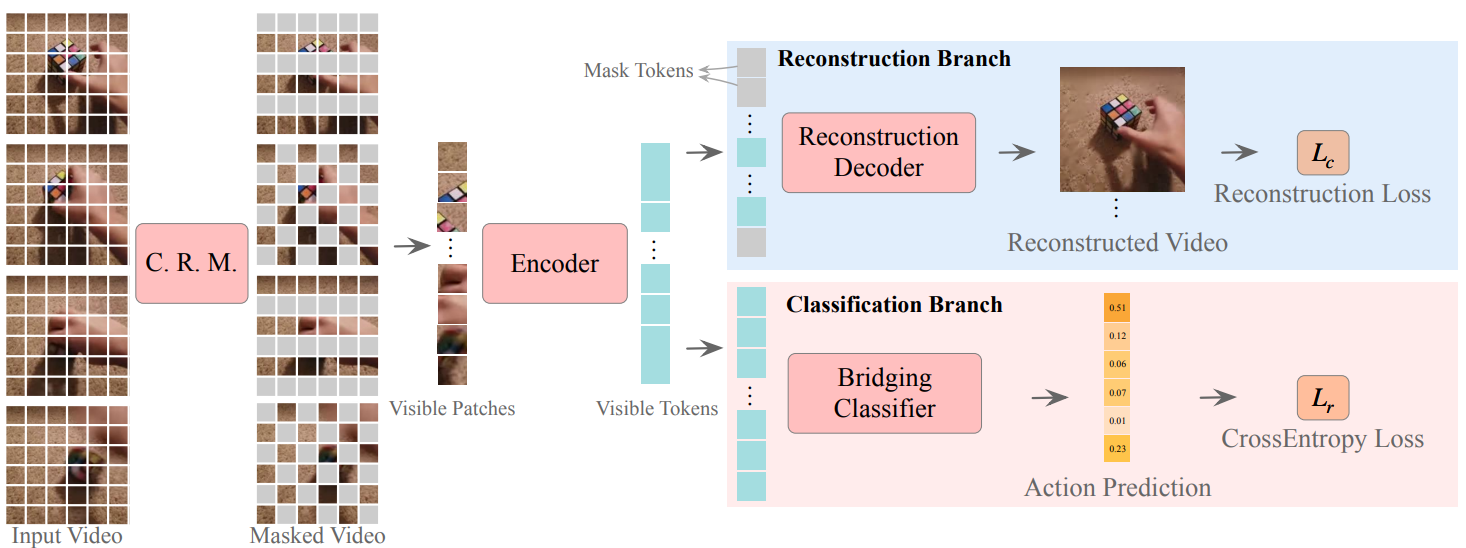
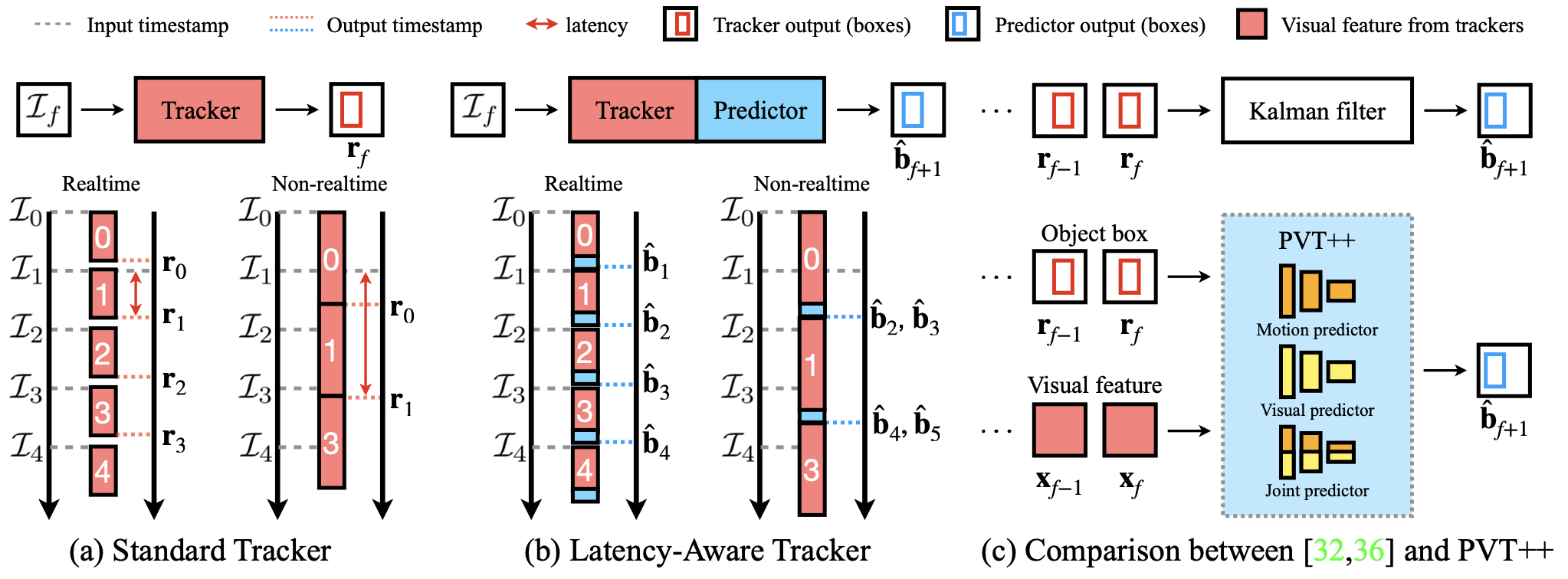
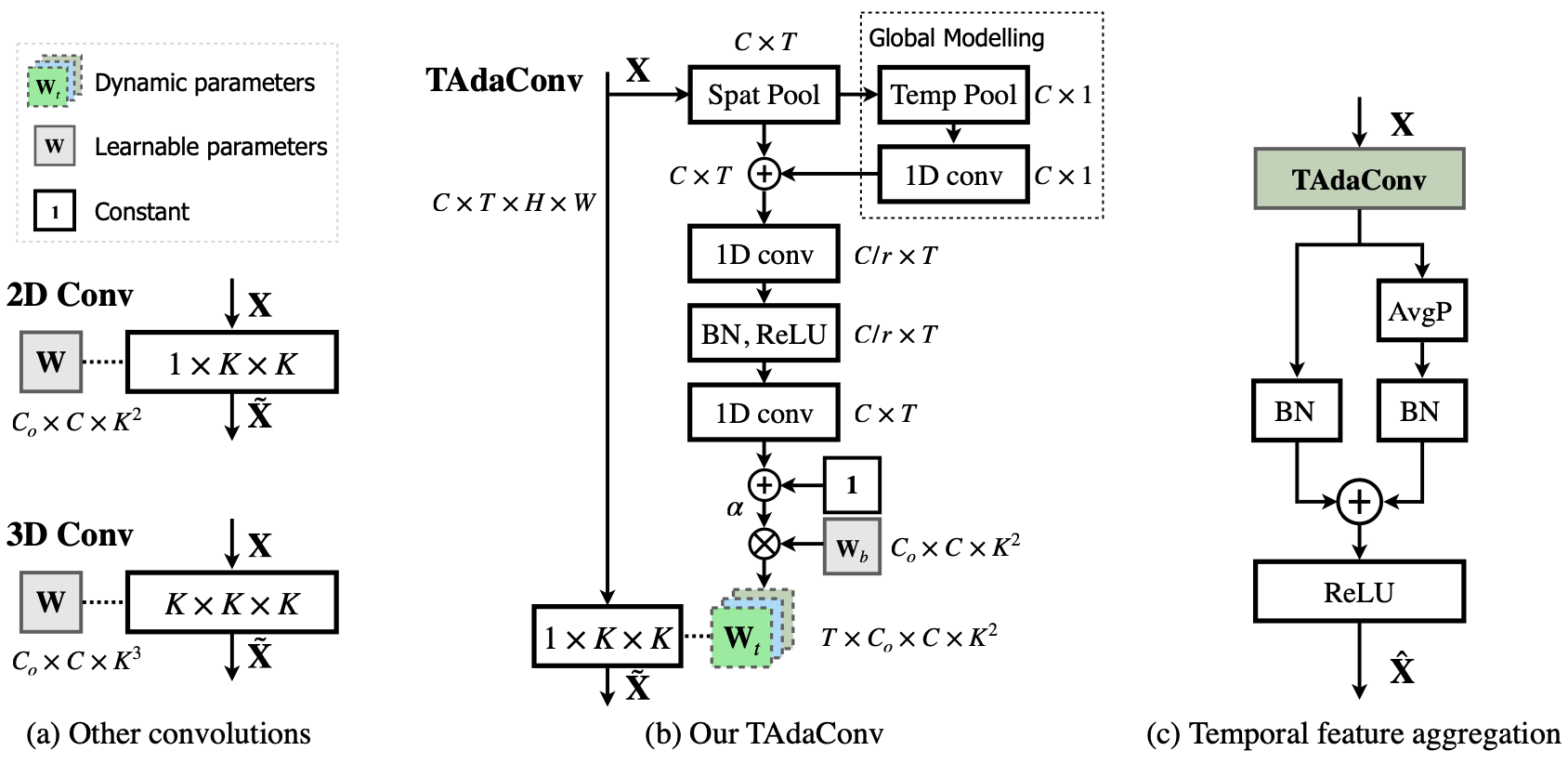
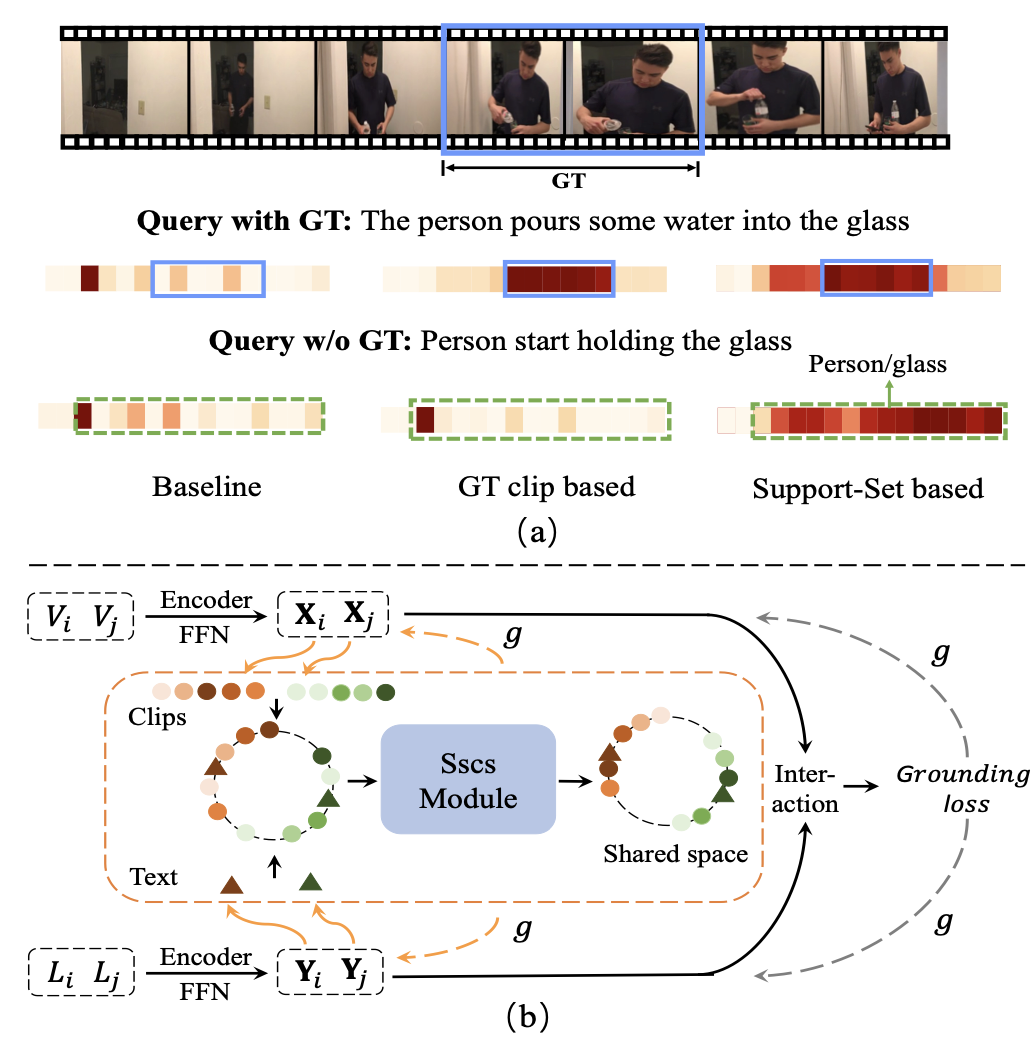
Support-Set Based Cross-Supervision for Video Grounding
Xinpeng Ding, Nannan Wang, Shiwei Zhang, De Cheng, Xiaomeng Li, Ziyuan Huang, Mingqian Tang, Xinbo Gao
ICCV 2021.