Huang Ziyuan 黄子渊
Huang Ziyuan 黄子渊
ABOUT
PUBLICATIONS
CONTACT
Video Grounding, Self-supervised Learning, Video Representations
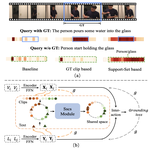
Support-Set Based Cross-Supervision for Video Grounding
[ICCV 2021] Tackling mutual exclusion in video grounding by support-set based cross-supervision.
Xinpeng Ding
,
Nannan Wang
,
Shiwei Zhang
,
De Cheng
,
Xiaomeng Li
,
Ziyuan Huang
,
Mingqian Tang
,
Xinbo Gao
Cite
PDF
Cite
×