Huang Ziyuan 黄子渊
Huang Ziyuan 黄子渊
ABOUT
PUBLICATIONS
CONTACT
1
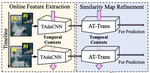
Towards Real-World Visual Tracking with Temporal Contexts
[TPAMI] Visual tracking framwork with low latency and high performance.
Ziang Cao
,
Ziyuan Huang
,
Liang Pan
,
Shiwei Zhang
,
Ziwei Liu
,
Changhong Fu
Cite
PDF
Code
PVT++: A Simple End-to-End Latency-Aware Visual Tracking Framework
[CVPR 2023] Real-world tracking approach addressing the latency issues.
Bowen Li
,
Ziyuan Huang
,
Junjie Ye
,
Yiming Li
,
Sebastian Scherer
,
Hang Zhao
,
Changhong Fu
Cite
PDF
Code
Website
MAR: Masked Autoencoders for Efficient Action Recognition
[TMM] Efficient masked action recognition model that reduces the computation of ViT by 53% with better performances.
Zhiwu Qing
,
Shiwei Zhang
,
Ziyuan Huang
,
Xiang Wang
,
Yuehuan Wang
,
Yiliang Lv
,
Changxin Gao
,
Nong Sang
Cite
PDF
Code
Learning from Untrimmed Videos: Self-Supervised Video Representation Learning with Hierarchical Consistency
[CVPR 2022] A contrasive learning framework leveraging rich information in long videos.
Zhiwu Qing
,
Shiwei Zhang
,
Ziyuan Huang
,
Yi Xu
,
Xiang Wang
,
Mingqian Tang
,
Changxin Gao
,
Rong Jin
,
Nong Sang
Cite
PDF
Code
Website
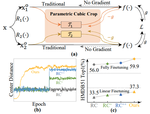
ParamCrop: Parametric Cubic Cropping for Video Contrastive Learning
[TMM] Parameterized cropping module for better contrastive learning in videos.
Zhiwu Qing
,
Ziyuan Huang
,
Shiwei Zhang
,
Mingqian Tang
,
Changxin Gao
,
Marcelo H. Ang Jr
,
Rong Jin
,
Nong Sang
Cite
PDF
Code
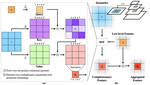
TAda! Temporally-Adaptive Convolutions for Video Understanding
[ICLR 2022] Empowering 2D convs in video models to have temporal modelling abilities.
Ziyuan Huang
,
Shiwei Zhang
,
Liang Pan
,
Zhiwu Qing
,
Mingqian Tang
,
Ziwei Liu
,
Marcelo H Ang Jr
Cite
PDF
Code
Website
Video
Multi-Scale Feature Aggregation by Cross-Scale Pixel-to-Region Relation Operation for Semantic Segmentation
[IEEE RA-L] Cross-scale feature aggregation by local self-attention.
Yechao Bai
,
Ziyuan Huang
,
Lyuyu Shen
,
Hongliang Guo
,
Marcelo H. Ang Jr
,
Daniela Rus
Cite
PDF
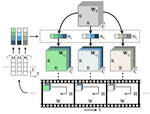
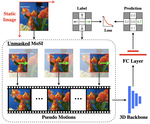
Self-supervised motion learning from static images
[CVPR 2021] Learning motion-centric video representation by classifying pseudo motions.
Ziyuan Huang
,
Shiwei Zhang
,
Jianwen Jiang
,
Mingqian Tang
,
Rong Jin
,
Marcelo H. Ang Jr
Cite
PDF
Video
Code
Released under EssentialMC2
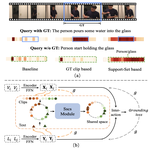
Support-Set Based Cross-Supervision for Video Grounding
[ICCV 2021] Tackling mutual exclusion in video grounding by support-set based cross-supervision.
Xinpeng Ding
,
Nannan Wang
,
Shiwei Zhang
,
De Cheng
,
Xiaomeng Li
,
Ziyuan Huang
,
Mingqian Tang
,
Xinbo Gao
Cite
PDF
AutoTrack: Towards High-Performance Visual Tracking for UAV with Automatic Spatio-Temporal Regularization
[CVPR 2020] Spatio-Temporal Regularization for constraining response maps in DCF-based trackers.
Yiming Li
,
Changhong Fu
,
Fangqiang Ding
,
Ziyuan Huang
,
Geng Lu
Cite
PDF
Code
»
Cite
×