 SSCS
SSCS
Abstract
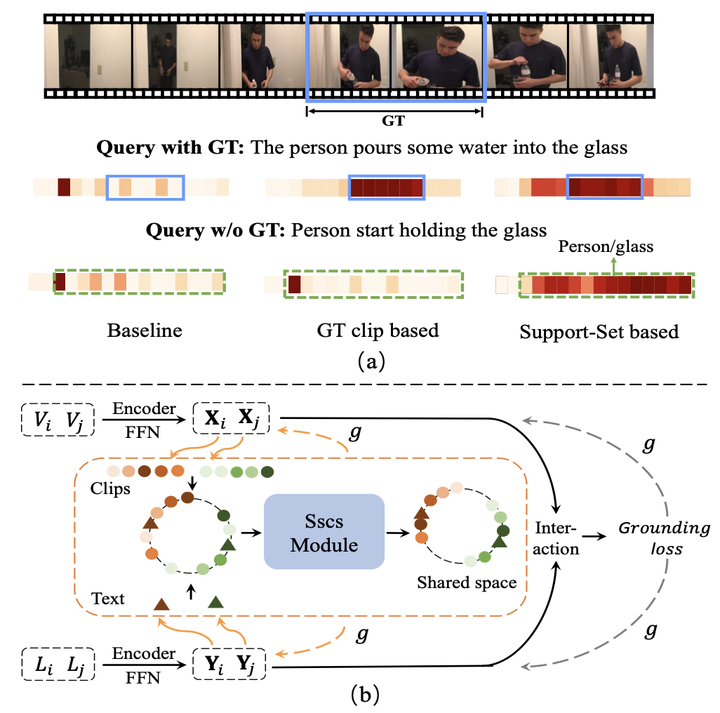
Current approaches for video grounding propose kinds of complex architectures to capture the video-text relations, and have achieved impressive improvements. However, it is hard to learn the complicated multi-modal relations by only architecture designing in fact. In this paper, we introduce a novel Support-set Based Cross-Supervision (Sscs) module which can improve existing methods during training phase without extra inference cost. The contrastive objective aims to learn effective representations by contrastive learning, while the caption objective can train a powerful video encoder supervised by texts. Due to the co-existence of some visual entities in both ground-truth and background intervals, ie, mutual exclusion, naively contrastive learning is unsuitable to video grounding. We address the problem by boosting the cross-supervision with the support-set concept, which collects visual information from the whole video and eliminates the mutual exclusion of entities. Combined with the original objective, Sscs can enhance the abilities of multi-modal relation modeling for existing approaches. We extensively evaluate Sscs on three challenging datasets, and show that our method can improves current state-of-the-art methods by large margins, especially 6.35% in terms of R1@ 0.5 on Charades-STA.